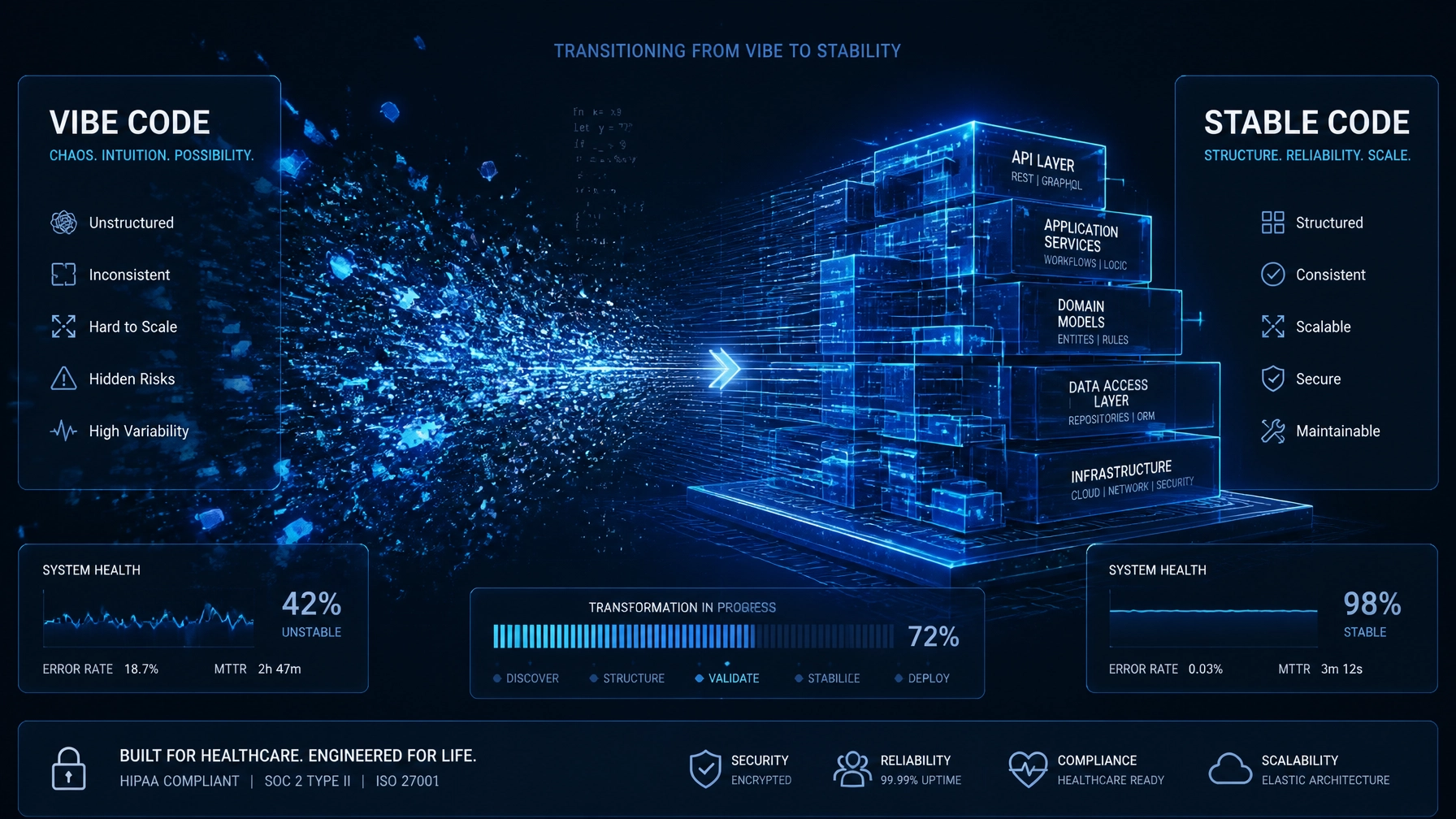
Something changed in clinical AI over the last few months. I don’t think enough founders noticed.
For about two years, the bar was simple. Does the demo work? If yes, you could raise on it. You could land a pilot on it. You could get a hospital excited on it.
That era is ending. And I think a lot of teams are going to get caught off guard.
Three things happened
Let me give you the facts first, then what I think they mean.
A Harvard and Stanford audit looked at AI models running in real hospitals. They found something they called a deployment gap. Models that scored great in testing lost accuracy fast once real patient data started flowing through them. Not a small drop. The kind that changes whether a tool is safe to use at all. If you’ve watched a system look perfect in dev and then stall the moment it touches production, the shape of this is familiar.
Then MIT put a number on something everyone already felt. Most AI pilots never deliver real value. In healthcare the list of dead ones is long, and some of those names raised enormous rounds. Big money, big teams, still could not make the jump from pilot to production.
Then a paper in Science compared a top model against real physicians on diagnostic reasoning. The model did well. That got the headlines. But the part nobody talked about was this: physicians using the model scored about the same as the model working alone. The human in the loop, the safety net everybody assumes is there, added almost nothing.
Three studies. Three angles. One story.
The model is not the hard part anymore. Everything around the model is the whole game now.
Why the bar was so low for so long
It helps to remember why “mostly works” was ever ok.
When this stuff was new, just getting an LLM to read a lab panel and summarize it correctly felt like magic. The first time you see it work, you forgive a lot. The bar was “can it do this at all.” Not “can it do this every single time, under every weird condition a hospital throws at it.”
Investors funded the magic. Pilots got signed on the magic. And for a while that was fine, because nobody had deployed at enough scale to see where the magic breaks.
That grace period is gone. Enough products have hit real hospital deployment now that we have data on what happens next. And what happens next is not dramatic. It is a slow bleed. Clinician trust drops a little at a time. Adoption stalls. And a security review surfaces problems the team never even tested for.
What “mostly works” actually looks like
Here is the part that fools people. “Mostly works” does not look like failure.
It looks like a great demo. A pilot that feels good. Screenshots the whole team is proud of.
Then real usage starts. A clinician asks the question a little differently than your test set did. Two sources contradict each other and the system just picks one, no flag. A lab value gets read without enough context. And the answer comes back confident, clean, well formatted, and subtly wrong.
Nobody catches it right away. Because it does not look broken. It looks like an answer.
That is the dangerous one. A system that fails loud gets fixed. A system that fails quiet, with a confident tone and nice formatting, just quietly loses trust until one day a clinician decides they don’t rely on it anymore. And by the time you notice adoption stalled, you are usually staring at the wrong metrics wondering why the numbers that looked so good in testing are not showing up in real use.
The questions are getting sharper
This is the part that matters if you sell into healthcare.
Two years ago hospital security teams asked if you had a BAA and if you were HIPAA compliant. That was the conversation.
Now they ask harder things. Where does your system break? What kind of input makes it break? What happens when two sources disagree? Can every answer trace back to evidence? Does the system know when it should not answer at all? Can you reproduce a failure when it happens?
Those are not compliance questions. Those are reliability questions. And most teams have never been asked them, which means most teams never built the answer.
The ones who can answer are starting to win deals faster. The ones who can’t are getting sent back with a remediation list, or losing to someone who can.
What this means if you are building
The hard truth is that the work that makes clinical AI reliable is mostly invisible. It does not show up in the demo. It does not make the pitch prettier. It is the boring architecture underneath. Retrieval that knows the difference between similar and relevant. Synthesis that refuses to guess past its evidence. A failure mode that raises its hand instead of hiding. An audit trail that lets you rebuild any answer the system ever gave.
None of that wins a demo. All of it decides if you survive production.
And here is something I have to admit about myself. After 25 years of building this stuff, a lot of these failure points are obvious to me the second I look at a system. So obvious that I sometimes forget they are not obvious to everyone. That is actually my blind spot, not my edge. The things I see instantly are exactly the things that blindside good teams, because they are heads down shipping features and nobody is looking at the seams.
The teams that get this early have a real advantage. Not because they go slower. Because they don’t rebuild after the security review. They don’t get surprised in enterprise evaluation. They know what to fix first. They have evidence ready when a buyer asks something hard. The kind of evidence you only get when you’ve tested your system the way you’d try to break it, not the way you’d try to ship it.
They can say, in plain words, “we know where this breaks and here is how we handle it.” That sentence is becoming the thing that actually moves a clinical AI deal forward. Not “our model is accurate.” Everybody says that. Nobody believes it anymore.
Where this goes
I think the next year splits clinical AI into two groups.
One group treats reliability as architecture. They build for the failure first, the happy path second. They assume the model will be wrong sometimes and design so the system catches itself when it is. These products survive procurement and earn trust and scale past the first hospital.
The other group keeps polishing the demo. Keeps shipping on “mostly works.” And keeps getting surprised, deal after deal, by questions they never thought to ask themselves.
The gap between those two groups is not talent. It is not funding. Some of the best funded teams in healthcare are squarely in the second group. The gap is whether you decided early that “mostly works” was not the finish line.
In healthcare it never was.
If you are building something and you are honestly not sure which group you are in, that is worth figuring out before a hospital figures it out for you. That is the work I do. Happy to talk it through.