Vibe code
Fast and fragile. Your team moves quick with AI coding tools, but there's no real architecture and no security model. A tech-debt bomb that goes off right before a deal or an audit.
Founder-led engineering for healthcare and AI
We turn ideas into scalable, hospital-ready software products, built with you from day one.

Built for the people who can't afford to get it wrong.
The problem
Compliance is the floor.
HIPAA and GDPR are table stakes, not features you bolt on later.
Clinicians need to trust it.
A doctor will not act on an answer they cannot trace back to a source.
Production is messy.
Clean demos hide the real-world data that breaks systems under load.
We build clinical software that holds up in production, embedded with your team from day one.
The alternatives
Two common paths leave you exposed. One ships real, compliant software.
Vibe code
Fast and fragile. Your team moves quick with AI coding tools, but there's no real architecture and no security model. A tech-debt bomb that goes off right before a deal or an audit.
Slide-deck consultants
They know the regulations cold and charge a fortune to hand you a PDF. Zero working code. The same problem you started with.
Senior leadership that builds with you. Production-grade clinical AI, compliant infrastructure, shipping in days. The only one that ships real code and understands clinical reality.
Compliant infrastructure, built in from the start.
We close the gap between strategy and shipped software. We don't just tell you what's broken. We embed and build.
Portfolio
Real platforms in production, from clinical decision support to maritime telemedicine.
Clinical decision support · Functional and longevity medicine
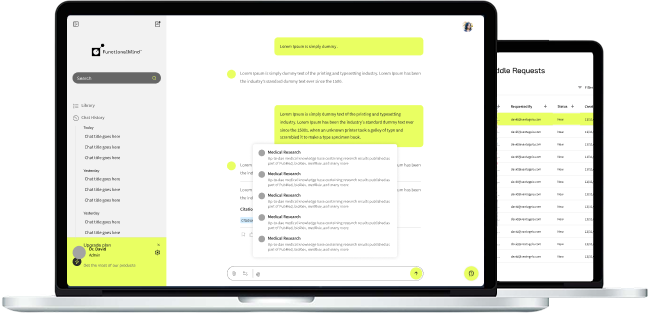
We built and still help run the architecture, engineering, and infrastructure behind FunctionalMind, a clinical decision support platform that uses evidence retrieval, RAG, and lab data to give clinicians grounded AI answers. Every answer ranks evidence by quality and traces back to its source. HIPAA and GDPR from day one. Built for the messy reality of clinical data, not a clean demo.
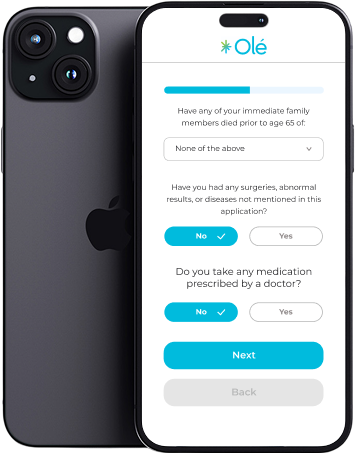
Four years and counting. We built and scaled the mobile and web apps that power Olé Life’s agent and member experience, including real-time health and life insurance quoting, policy management, and bilingual workflows across both platforms.
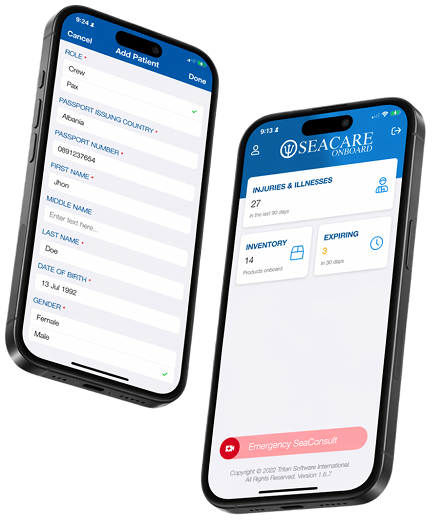
Built SeaCare’s maritime healthcare case management platform from the ground up, for a setting where connectivity is limited and getting care wrong has real consequences. Onboard crew workflows, telemedicine coordination, and peer-to-peer live video and audio for remote medical assist.
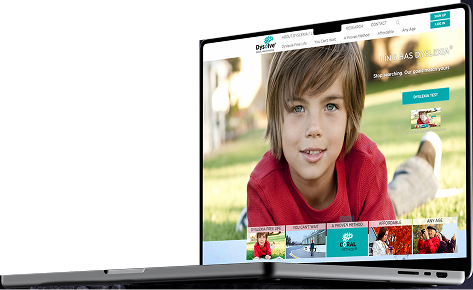
Architected and built Dysolve’s interactive learning platform, a scalable, therapy-oriented system for dyslexia intervention through AI-driven gamification and adaptive content. Built to grow with the program, not just to demo well.
Took a women’s health concept from MVP to a production-ready platform built around predictive ML models for menopause forecasting. We led technical direction, rebuilt the infrastructure for scale, and drove the HIPAA compliance work, so the team could focus on growth.
What we build
Four things we do over and over for healthcare teams. Each one ends in working software.
Zero to one
Early-stage healthcare concepts turned into real platforms, built right from day one.
Agentic Enabled Engineering
AI agents building on real architecture and testing, so speed produces stable software instead of tech debt.
AI your clinicians trust
Retrieval pipelines and testing that keep AI outputs accurate, traceable, and grounded.
Compliance baked in
HIPAA, GDPR, and healthcare security built into the infrastructure from the start.

Technology and partners
 Apple HealthKit
Apple HealthKit  Google Fit
Google Fit 


By the numbers
25
Years in healthcare engineering
57
Products shipped
HIPAA + GDPR
Compliant from the infrastructure up
What clients say
The people we work with are building real systems for real patients and real clinicians. They didn't need another consulting deck. They needed someone who had already seen what breaks inside real healthcare systems and knew where to look first.
"Sam and his team move fast, communicate clearly, and bring strong technical judgment to complex healthcare AI work."
"A unique combination of skills and an amazing team. Throughout the project, they never missed a deadline."
"Sam and his team were thoughtful, responsive, and easy to work with. They brought clarity and execution when it mattered."
"Six weeks alongside Sam took our platform from concept to something real. Deep technical judgment, every step."
"Sam and his team built our data warehouse the right way, clean, scalable, and exactly what we needed. They were responsive, pragmatic, and a genuine pleasure to work with."
How we engage
Lead and build.
We own the technical strategy and roadmap, embed with your team or bring a specialized pod, and ship production-ready code in days, not months.
Pick this when you are building something new and need senior engineering leadership from day one.
Review and remediate.
We go deep into your codebase, find every compliance, safety, and scaling risk that's holding you back, and deploy the fixes that make your system solid.
Pick this when you have already built something and need it made hospital-ready before a deal or an audit.





Ready when you are
Bring your idea. We turn it into scalable, hospital-ready software your clinicians can stand behind, embedded with your team from week one.
Skip the corporate sales dance. On a free 20-minute call we'll dig into your biggest technical hurdle and map the path to production.






