For the last three weeks I’ve been writing about where clinical AI systems break.
How they fail hospital security reviews. How RAG pipelines silently leak PHI. How real-world testing surfaces edge cases your test suite never imagined.
If you’ve been reading along, you might be sitting there with a question. A fair one.
“OK Sam. Enough about how it breaks. What does a system that actually works look like?”
Let me try to answer that.
The honest answer
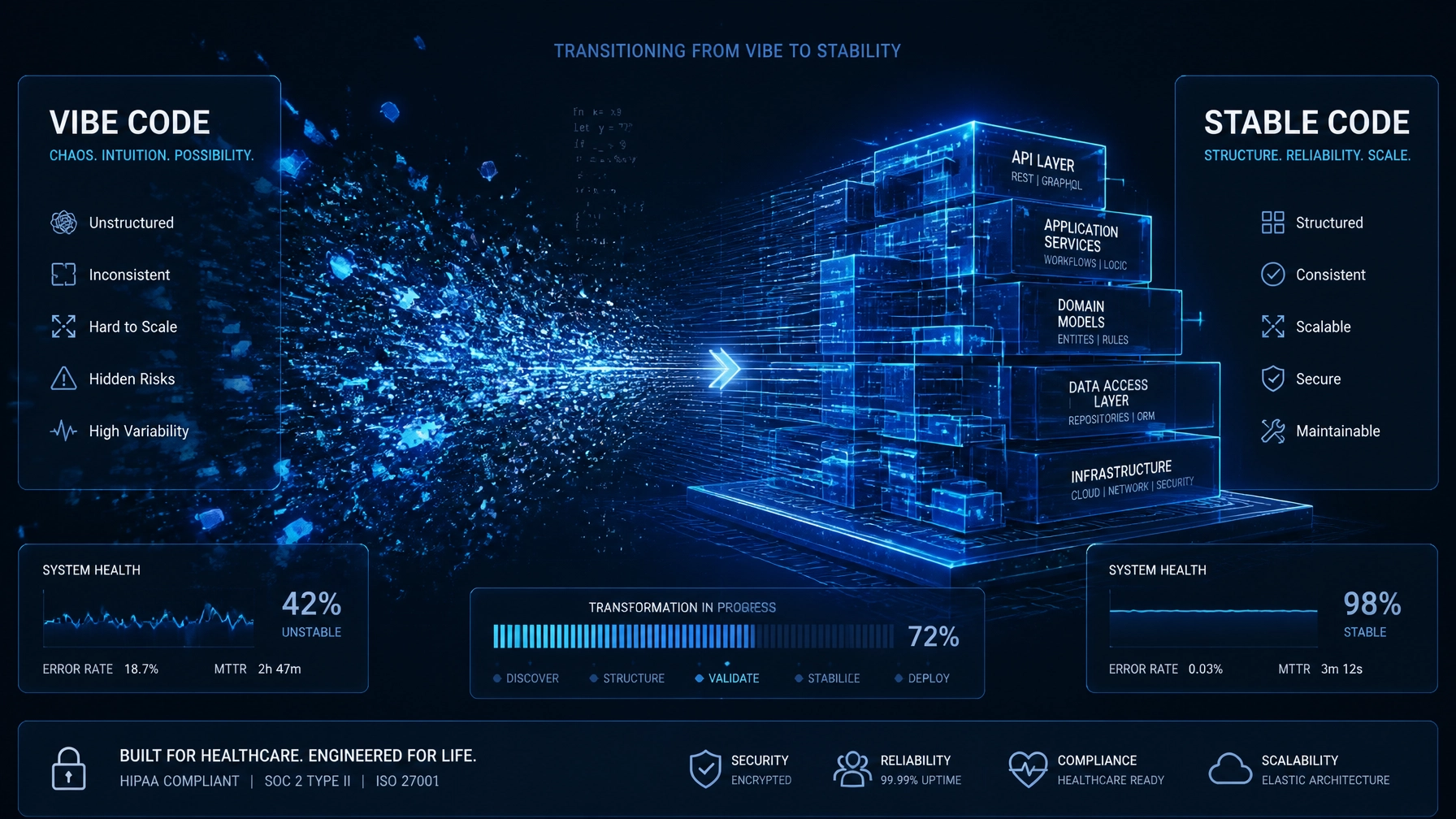
A clinical-grade AI system is not a different model. It is not a magic prompt. It is not a fancier vector database.
It is an architecture that assumes things will go wrong, and is designed to fail safely when they do.
Sounds boring, I know. But this is the part most clinical AI products get wrong, and it is the part that decides whether your system survives a hospital’s review or dies in pilot.
A clinical-grade system has a few things almost every demo-grade system is missing. Let me walk through them.
1. A curated corpus, not a content dump
Most clinical AI products start with “let’s just embed all the medical content we can find.”
That is the first mistake.
In healthcare, the source of an answer matters as much as the answer itself. A patient forum post and a Cochrane systematic review carry the same semantic weight in a vanilla vector database. To a generic embedding model, they look similar. To a clinician, they are not even in the same universe.
A clinical-grade system curates the corpus before it indexes anything. Source selection. Source ranking. Normalization. Enrichment with metadata about authority, recency, and clinical applicability.
If you cannot tell me where every chunk in your vector database came from and why it is in there, you do not have a clinical retrieval system. You have a search engine for medical-flavored text.
There is a difference. A pretty big one.
2. Hybrid retrieval, not pure semantic search
Semantic similarity is not the same as clinical relevance.
Ask your system about metformin dosing for elderly patients with reduced kidney function. A pure vector search will happily return content that talks about metformin. Some of it about pediatric use. Some of it about diabetes prevention. Some of it about pharmacology in animal models.
It is all metformin-adjacent. It is also useless to the clinician asking the question.
A clinical-grade system uses hybrid retrieval. Keyword search and semantic search working together, each catching what the other misses. Plus filters that constrain by domain, by patient population, by document type. We wrote about why naive RAG falls apart in clinical settings and why the gap between “semantically similar” and “clinically relevant” is where most systems break.
Not because it is fancier. Because the cost of irrelevant retrieval in a clinical context is a wrong answer.
3. Evidence ranking, not equal weighting
Once you have retrieved candidate sources, somebody has to decide which ones the model should actually use.
Most systems do this implicitly. They throw the top-k chunks into the prompt and hope the model figures it out. It usually doesn’t. The model treats every chunk as equally authoritative, because nothing in the architecture told it otherwise.
A clinical-grade system ranks evidence deterministically before synthesis. A peer-reviewed clinical guideline outranks a textbook chapter. A textbook chapter outranks a case report. A case report outranks a forum post. Recency matters. Source authority matters. The match between source and query context matters.
This is not a feature you bolt on at the end. It is a design constraint applied at the retrieval layer. When the model writes its answer, it is writing from a pre-ranked stack of evidence, not a soup of similar text.
4. Bounded synthesis, not creative writing
Here is where most clinical AI products get themselves into real trouble.
The model is told to “answer the question based on the retrieved documents.” Sounds reasonable. But unless your prompt and your architecture explicitly constrain it, the model will fill in gaps. Quietly. Confidently. With plausible-sounding content that has no source.
In a casual chatbot, that is a feature. The model is being helpful.
In a clinical workflow, that is a hallucination, and a patient safety risk.
A clinical-grade system uses bounded synthesis. The model summarizes what was retrieved. It does not speculate beyond it. If the retrieved set does not contain the answer, the system says so. It does not invent the answer.
This is one of those design decisions that sounds restrictive until you watch a clinician adopt the system. The trust comes faster, because the system stops trying to be clever.
5. Explainability, not opacity
Every answer in a clinical-grade system has a paper trail.
Which sources were retrieved. Which ones were ranked high. Which ones the model actually used. The reasoning path from question to answer.
A clinician should be able to click on any output and see the chain back to its evidence. So should an auditor. So should a procurement reviewer. So should the team designing the system, when something goes wrong and they need to figure out why.
This is the layer most teams skip because it does not show up in the demo. It only shows up in production. And in clinical procurement reviews. And in the moment a clinician decides whether to trust the system.
Skipping explainability is a choice you can make at the architecture stage. It is not a choice you can make later, because adding it after the fact means rebuilding most of what you have already shipped.
6. A failure mode that fails safely
I wrote about this last week, but it belongs in this list too.
A clinical-grade system has a defined behavior for when it is not sure. It does not just return its best guess. It surfaces uncertainty, asks for review, or routes to a human.
That sounds like a small thing. It is not. The willingness to design “I don’t know” as a first-class output is the single biggest difference between a system that gets adopted in clinical workflows and one that gets quietly turned off three months after launch.
What this adds up to
If you stack these layers together, you get something that does not look like most AI products on the market right now.
It is slower to build. It is harder to demo. It does not look as impressive in a 60-second video.
But it survives the things that kill most clinical AI products. Security reviews. Compliance reviews. Clinical validation. Real-world inputs that do not match your test set. The first time something goes wrong in production and somebody asks why.
The teams that ship clinical AI well are the teams that build for the system, not the model. The model is one component. A useful one. But it is one component in a pipeline that has to handle preprocessing, retrieval, ranking, bounded synthesis, explainability, fallback, and audit logging.
Each layer protects the next one. Each layer is also a place where things can go wrong if you treat it as an afterthought.
Where to start
If you are reading this and thinking “we don’t have most of these,” that is fine. Most teams don’t. The ones I work with usually have two or three of these layers in some form, and the others are either missing or duct-taped together.
The starting point is honest mapping. Walk through your current architecture and ask, layer by layer, what you actually have. Not what you intend to build. What is in production today.
For a lot of teams, that walkthrough is uncomfortable. You discover that what you thought was your retrieval layer is actually a thin wrapper around a vector database with no ranking logic. You discover that your “explainability” is a list of chunk IDs nobody can interpret. You discover that your synthesis layer has no constraints at all, and the only thing keeping the model honest is the prompt.
That is normal. It is also fixable. But you cannot fix what you have not mapped.
If you want a second set of eyes on what you have actually built, here’s exactly what an architecture review looks like. Two weeks. Full system map. A clear plan to fix, build, or scale. From there, you decide what to do.
Either way, the architecture is the product. Build for it.